『ゼロから作る Deep Learning』を読んで C# で実装したみたくなった続き。 今度はニューラルネットワークで使う関数に挑戦してみた。
実装するのは活性化関数であるシグモイド関数、ReLU 関数。 そして出力層で使うソフトマックス関数。 あとおまけでステップ関数も。
ひとまず畳み込まないニューラルネットワークを作りたいので、 行列を扱う活性化関数として実装。 ソフトマックス関数は出力層で使うので、こいつだけはベクトルを扱う。
using MathNet.Numerics.LinearAlgebra; using System; using System.Linq; namespace NeuralNetworkSample { class Program { static void Main(string[] args) { var m = Matrix<double>.Build.Random(3, 3); Console.WriteLine(m); Console.WriteLine("step function"); Console.WriteLine(StepFunction(m)); Console.WriteLine("ReLU"); Console.WriteLine(ReLU(m)); Console.WriteLine("sigmoid"); Console.WriteLine(Sigmoid(m)); var v = m.Column(0); Console.WriteLine("softmax"); Console.WriteLine(Softmax(v)); Console.ReadLine(); } public static Matrix<double> StepFunction(Matrix<double> a) { // 行列の要素ごとの演算に Map を使う return a.Map(x => x > 0 ? 1.0 : 0.0); } public static Matrix<double> Sigmoid(Matrix<double> a) { return a.Map(x => 1 / (1 + Math.Exp(-x))); } public static Matrix<double> ReLU(Matrix<double> a) { return a.Map(x => Math.Max(x, 0)); } public static Vector<double> Softmax(Vector<double> a) { var c = a.Max(); // ベクトルの要素ごとの演算にも Map を使う var exp_a = a.Map(x => Math.Exp(x - c)); var sum_exp_a = exp_a.Sum(); var y = exp_a.Map(x => x / sum_exp_a); return y; } } }
実行結果はこちら。
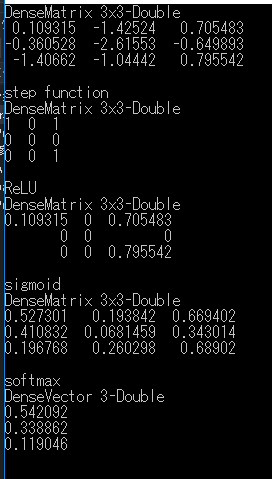
正しく動いている、ように見える。 今回も Math.NET Numerics を使ってみたが、NumPy と比べると前回以上に冗長に感じた。 NumPy はよくできたライブラリだ。